
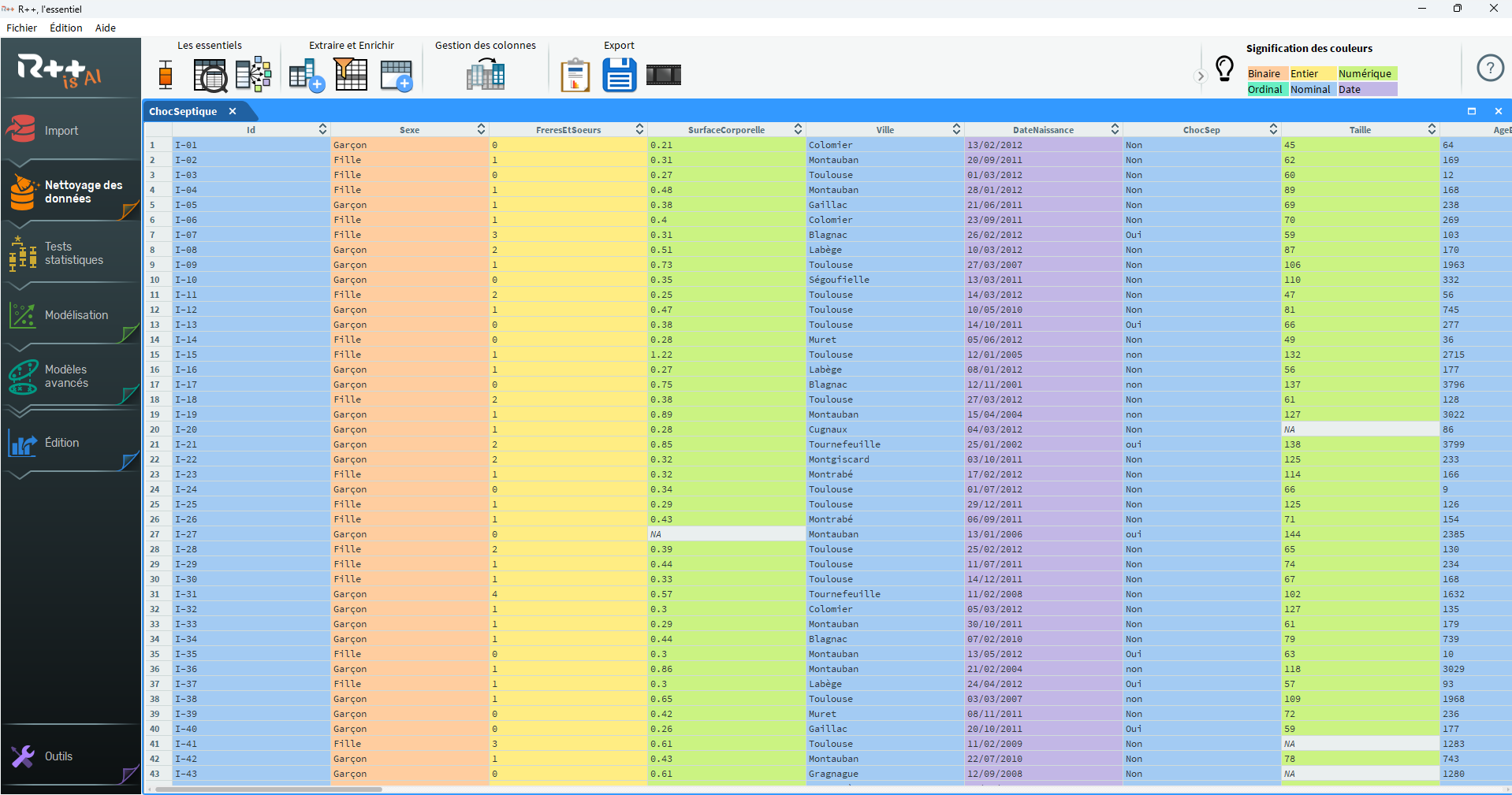
Dans toute étude clinique, la qualité des analyses statistiques dépend directement de la qualité des données. Avant de penser aux tests, modèles ou régressions, il existe une étape incontournable : le nettoyage méthodique de la base.
Erreurs de saisie, modalités incohérentes, valeurs aberrantes, codages hétérogènes… Ces anomalies peuvent modifier les distributions, biaiser les estimateurs, ou conduire à des interprétations erronées.
C’est une étape chronophage, souvent sous-estimée, mais statistiquement essentielle.
👉 Bonne nouvelle : Le module Nettoyage des données de R++ a été développé pour rendre cette phase plus rapide et plus structurée, en conservant une logique rigoureuse conforme aux exigences méthodologiques des études cliniques.
Exemple : une variable “Féminin” / “Feminin” / “F” ?
Une source fréquente d’erreurs dans les bases cliniques concerne les catégories mal orthographiées ou hétérogènes.
D’un point de vue statistique, ces variations artificielles augmentent le nombre de modalités et peuvent donc modifier les analyses statistiques.
Solution : Vous pouvez facilement repérer ces incohérences, à l’aide du graphique, du typeur ou encore du code couleur et corriger cela en fusionnant d’un simple drag & drop les modalités équivalentes.
Les valeurs aberrantes (outliers) peuvent avoir un impact majeur sur :
Exemple : un IMC à 220 ou un âge de 3 ans dans une cohorte adulte.
R++ propose deux approches complémentaires :
L’objectif n’est pas de supprimer mécaniquement les valeurs extrêmes, mais de les identifier, puis de permettre au chercheur d’évaluer leur légitimité clinique ou leur caractère anormal.
Un problème classique dans les bases cliniques est la présence de variables codées de façon incohérente :
Ces erreurs peuvent entraîner :
Dans R++, chaque type de variable est affiché avec un code couleur intelligent permettant de repérer immédiatement les erreurs et de les corriger, avant même de lancer la moindre analyse.
Avant une analyse, il est souvent nécessaire de :
Exemple : ne garder que la population féminine (ou masculine) ou n’analyser que les participants avec un IMC normal ou supérieur.
En deux clics, vous obtenez une nouvelle colonne ou une sous-base prête à être analysée.
En recherche clinique, la traçabilité est un élément méthodologique essentiel. Toute transformation de la base doit pouvoir être justifiée et reproduite.
Le module génère automatiquement un rapport de nettoyage qui liste :
Ce rapport peut être joint à un dossier méthodologique, un rapport d’étude, ou conservé en interne pour assurer la reproductibilité des analyses.

Le nettoyage des données est l’un des prérequis fondamentaux de toute analyse statistique robuste. Le module dédié de R++ permet de valider cette étape de manière optimale et facilité.


Want to see how HCI can revolutionize statistical analysis?
Our team is committed to contact you within 24 hours.